
Retrieval-Augmented Generation (RAG) with Llama 2 using Google Colab Free-Tier
Just show me the code!! As always, if you don’t care about the post I have uploaded the source code on my Github. Link to this Notebook
Introduction
Large language models (LLM), like Llama and GPT, usually learn from all sorts of information on the internet like wikipedia, reddit, stackoverflow etc. But, when it comes to specific knowledge like enterprise knowledge, they’re not the best. Instead of going through the hassle of training a whole new model, there’s a cool and easy trick called Retrieval-Augmented Generation (RAG).
RAG lets you give extra info to your large language models without making them go through training again. It’s like a shortcut! You grab info from places like document stores, databases, or APIs.
In this blog, we will see how we can implement an Retrievel Based Augmentation using a free-tier Google Colab notebook. Note, that this is only a Proof of Concept to get a better understanding behind RAG. Since this notebook is executable on Colab, you can play around to get a better intuition behind RAG. You’ll find out:
- Why RAG is useful
- How to turn a document into embeddings
- Storing those embeddings in a vector database
- Putting the vector database to work with a language model (RAG)
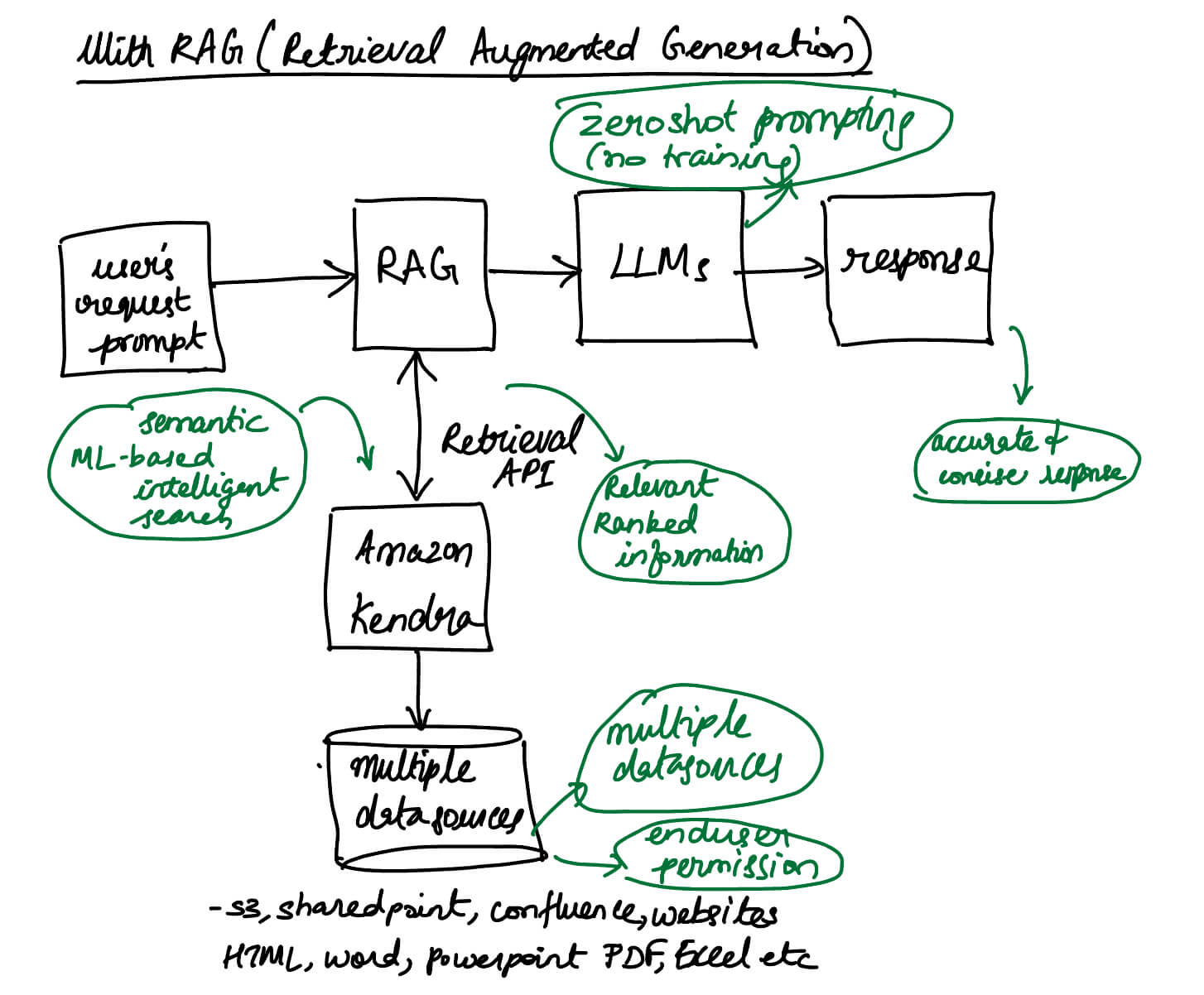
How does RAG work?
RAG, short for Retrieval-augmented Generation—an AI framework aimed at enhancing how Large Language Models (LLMs) respond. RAG elevates the quality of LLM responses by integrating both their intrinsic knowledge and insights from external sources.
When implementing RAG, the usual practice involves pairing it with a standard LLM, such as Llama or GPT.
Here’s the breakdown: During the retrieval phase, a sophisticated algorithm locates pertinent information based on the user’s query. The source could be public data like the internet or a collection of private documents.
Moving on to the generation phase, the LLM incorporates both the retrieved information and its internal knowledge to craft a comprehensive answer. Additionally, it has the capability to provide source links, promoting transparency in the response.
RAG vs Fine-Tuning
RAG and fine-tuning stand out as the top two methods for integrating fresh information into Large Language Models (LLMs). Both involve leveraging additional data, but they employ distinct approaches.
In the case of fine-tuning, there’s an extra round of training with the new data. This results in a revamped LLM model tailored to the new information, replacing the original model.
On the other hand, RAG takes a different route. It integrates the new data directly into the prompt, avoiding any alterations to the underlying model.
-
RAG comes out as the more budget-friendly option compared to fine-tuning. The latter involves training a typically large LLM, contributing to higher costs.
-
Both methods can deliver solid performance, but fine-tuning generally demands more effort to achieve it.
-
Both RAG and fine-tuning carry the risk of providing inaccurate information. However, RAG offers more control over hallucination by offering more accurate context information.
-
RAG takes the lead in transparency. The LLM remains fixed and unaltered, with the ability to respond with new information controlled by the quality of retrieval and prompt construction.
RAG Workflow
Employing an RAG workflow enables an LLM to respond to queries based on documents it hasn’t encountered before.
Here’s how it works: In the RAG workflow, documents undergo segmentation into sentence chunks. These chunks are then transformed into embeddings essentially a set of numerical values using a sentence transformer model. Subsequently, these embeddings find a home in a vector database, equipped with indexing for swift search and retrieval.
The RAG pipeline is powered by LangChain RetrievalQA, utilizing similarity search to match questions against the database. The identified sentences, along with the question, serve as input for the Llama 2 Chat LLM.
This synergy allows the LLM to address questions grounded in the document, thanks to RAG’s vector search pinpointing relevant sentences and incorporating them into the prompt!
It’s essential to note that implementing RAG offers various approaches, and the usage of a vector database is just one among many.
Getting Access to LLlama 2 LLM
- Complete the Llama access request form
- Submit the Llama access request form.
- Make sure to include both Llama 2 and Llama Chat models, and feel free to request additional ones in a single submission. Be sure to use the email address linked to your HuggingFace account.
- Normally, you can expect approval via email within an hour.
- Once you have approval, Go to the Access token page. Create a new one or use an old one. Save this access token somewhere safe. You will be using this token in the next step to access the Llama2 model.
A Note on GPU RAM Consumption
Since we are trying to run the model on Google Colab free tier account which provides a 16GB T4 GPU, we should be cognizent of which model we are loading and how much memory it takes up. Remember to calculate GPU RAM required to load the parameters. For example, loading a Llama2 7B Chat model on a standard 16bit floating point will cost us 14 GB of RAM (7B * 2Bytes(for 16bits) = 14GigaBytes). We have already exhausted 14GB of our 16GB RAM just for loading the parameters of our base llama2 model. This means that we are left with only 2GB of RAM for rest of our execution and other things. Thus if we try to load a LLama2 7B model on to Google Colab free tier account with 16GB T4 GPU, our kernal will crash during inference. Then how do we load our Llama 2 on Google Colab? Do I need to pay for additional GPU RAM? No Need. Keep reading.
There is something called Quantization. It is a way to reduce the memory consumed for storing a floating point number. To understand the intuition behind quantization, take the value “pi” which can be precisingly as “3.14159265359”. But this would take up more bits for storage. We can also reprepresent it as “3.14” which would take up lot less space but we would lose precision. The idea behind quantization is similar. Instead of using up 16bits, there is a quantization technique called “GPTQ” which reduces this down to just 4-5bits. You can read more about this in this paper here.
Now using this GPTQ technique, our new RAM consumption for a Llama2 7B model is ~4GB. With Google Colab free tier account, we would have a left over of 12GB to work with. This means our inferences will not crash.
Now you might ask where do I find a reduced Llama2 model with the GPTQ technique. The answer is at HuggingFace Hub which hosts a lot of open source models including Llama2. A user named “TheBloke” has converted the open source Llama2 models into GPTQ and provided them via Hugging face Hub. We can reference the model directly using “TheBloke/Llama-2-7b-Chat-GPTQ” and reference it in our AutoModelForCausalLM class. Remember to pass your Hugging face access token as the model parameter otherwise your execution will be denied.
Part-1: Setting up the Model
We can setup the model quickly using these two lines. With this code we load a pre-trained causal language model using the specified model name, move it to a GPU device (by specifying device_map=0), set the torch data type and also pass the Hugging Face access token we obtained in the previous step. Note how we specify “torch_dtype=torch.float16” yet, the function ignores this since the model we are loading is a GPTQ model.
Setup Model
mn = "TheBloke/Llama-2-7b-Chat-GPTQ"
model = AutoModelForCausalLM.from_pretrained(mn, device_map=0, torch_dtype=torch.float16, token=hf_token)
Now if you try running nvidia-smi you can see that the model loading has take up only 4GB of the ram space.
Setup Tokenizer
Before we dig deeper into tokenizer, lets setup a tokenizer so we can see the naked tokens first to get a better undersetanding of how this querying works with LLMs. In the below code, we set up a tokenizer using the AutoTokenizer from HuggingFace. AutoTokenizer class provides a convenient way to load the correct tokenizer class for a given pre-trained model. We don’t need to remember the exact tokenizer class for each pre-trained model. We just need to know the name of the pre-trained model and AutoTokenizer will take care of it.
Once we initialize our Tokenizer we pass in a text prompt, tokenizes it using the specified tokenizer, and print the returned tokens as PyTorch tensors. return_tensors=”pt” parameter specifies that the output should be PyTorch tensors. We could also specify use_fast=True parameter which indicates that the fast tokenizer implementation should be used.
tokr = AutoTokenizer.from_pretrained(mn, token=hf_token)
prompt = "write me a statement of work for Genesys"
toks = tokr(prompt, return_tensors="pt")
toks
{'input_ids': tensor([[ 1, 2436, 592, 263, 3229, 310, 664, 363, 5739, 267, 952]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
From above, we can see that the tokenizer has converted our string input into numeric tokens which has a length of 11. The input_ids corresponds to the tokenized input IDs, a 2D PyTorch tensor, where each element represents a token ID. ‘attention_mask’ corresponds to the attention mask, is a 2D PyTorch tensor, where each element is either 1 or 0, indicating whether the corresponding token should be attended to (1) or masked (0). In this case, all tokens have a value of 1, indicating full attention.
In the below code, we generate text using the LLM model, utilizing the provided input tokens (toks), and move the result from the GPU to the CPU. Unlike Humans, LLMs can only understand numerical input like tokens. This is why we are feeding input tokens while the model generates output tokens. Tokenization allows for representing variable-length sentences or documents as sequences of fixed-size tokens, making it easier to feed into a neural network.
During tokenization, each token is mapped to an embedding vector. These embeddings capture semantic information about the token and its context. By representing words as vectors, language models can understand and generalize relationships between words and phrases.
%%time
res = model.generate(**toks.to("cuda"), max_new_tokens=500).to('cpu')
res
CPU times: user 4min 25s, sys: 2min 12s, total: 6min 38s
Wall time: 6min 43s
tensor([[ 1, 2436, 592, 263, 3229, 310, 664, 363, 5739, 267,
952, 13, 13, 29902, 626, 3063, 363, 263, 3229, 310,
664, 363, 5739, 267, 952, 29892, 508, 366, 3113, 3867,
592, 411, 263, 4472, 29973, 13, 13, 29903, 545, 29892,
1244, 338, 263, 4472, 363, 263, 3229, 310, 664, 363,
5739, 267, 952, 29901, 13, 13, 14473, 310, 5244, 363,
5739, 267, 952, 1954, 14607, 13, 13, 1546, 518, 4032,
4408, 29962, 322, 518, 13696, 499, 424, 4408, 29962, 13,
13, 2539, 29901, 518, 2539, 310, 4059, 276, 882, 29962,
13, 13, 25898, 29901, 13, 13, 29961, 4032, 4408, 29962,
313, 1552, 376, 4032, 1159, 322, 518, 13696, 499, 424,
4408, 29962, 313, 1552, 376, 13696, 499, 424, 1159, 526,
18055, 964, 445, 6666, 882, 310, 5244, 313, 1552, 376,
6156, 29956, 1159, 363, 278, 5314, 310, 263, 5739, 267,
952, 1650, 363, 278, 12477, 29889, 450, 6437, 310, 445,
7791, 29956, 338, 304, 27887, 278, 6874, 310, 664, 29892,
12021, 1849, 29892, 5335, 5570, 29892, 322, 916, 1820, 3161,
310, 278, 2060, 29889, 13, 15289, 310, 5244, 29901, 13,
1576, 6874, 310, 664, 363, 445, 2060, 7805, 278, 1494,
29901, 13, 13, 29930, 16052, 362, 322, 5285, 310, 278,
5739, 267, 952, 1650, 13, 29930, 8701, 2133, 322, 5849,
310, 278, 5739, 267, 952, 1650, 304, 5870, 278, 12477,
29915, 29879, 2702, 11780, 13, 29930, 4321, 292, 322, 11029,
1223, 18541, 310, 278, 5739, 267, 952, 1650, 13, 29930,
26101, 322, 2304, 363, 278, 12477, 29915, 29879, 13925, 373,
278, 671, 310, 278, 5739, 267, 952, 1650, 13, 29930,
3139, 5684, 5786, 3734, 304, 9801, 278, 9150, 5314, 310,
278, 5739, 267, 952, 1650, 13, 13, 13157, 2147, 1849,
29901, 13, 1576, 1494, 12021, 1849, 526, 3806, 304, 367,
8676, 491, 278, 2138, 499, 424, 408, 760, 310, 445,
2060, 29901, 13, 13, 29930, 16052, 362, 322, 5285, 310,
278, 5739, 267, 952, 1650, 13, 29930, 8701, 2133, 322,
5849, 310, 278, 5739, 267, 952, 1650, 304, 5870, 278,
12477, 29915, 29879, 2702, 11780, 13, 29930, 4321, 292, 322,
11029, 1223, 18541, 310, 278, 5739, 267, 952, 1650, 13,
29930, 26101, 322, 2304, 363, 278, 12477, 29915, 29879, 13925,
373, 278, 671, 310, 278, 5739, 267, 952, 1650, 13,
29930, 3139, 5684, 5786, 3734, 304, 9801, 278, 9150, 5314,
310, 278, 5739, 267, 952, 1650, 13, 13, 13711, 5570,
29901, 13, 1576, 2060, 338, 3806, 304, 367, 8676, 2629,
518, 2230, 2557, 29962, 515, 278, 2635, 310, 445, 7791,
29956, 29889, 450, 1494, 2316, 342, 2873, 526, 3806, 304,
367, 14363, 2645, 278, 2060, 29901, 13, 13, 29930, 518,
29316, 27744, 29871, 29896, 29962, 448, 518, 2539, 29962, 13,
29930, 518, 29316, 27744, 29871, 29906, 29962, 448, 518, 2539,
29962, 13, 29930, 518, 29316, 27744, 29871, 29941, 29962, 448,
518, 2539, 29962, 13, 13, 15467, 358, 11814, 29879, 29901,
13, 1576, 2138, 499, 424, 674, 367, 12530, 518, 14506,
29962, 363, 278, 13285, 310, 445, 2060, 29889, 14617, 358,
674, 367, 1754, 297, 518, 6252, 1860, 29962, 408, 4477,
29901, 13, 13, 29930, 518, 23271, 358, 29871, 29896, 29962,
448]])
Note: There is also a T5Tokenizer. The difference between the two is, while the T5Tokenizer prepends a whitespace before the eos token when a new eos token is provided, the AutoTokenizer maintains the usual behaviour.
Since we, Humans, do not understand token language :), we use the tokenizer to do the opposite for us, convert the tokens to text using “decode()”. The tokenizer is able to do this since it uses a vocabulary to map tokens to words and vice versa. The vocabulary is a predefined set of unique tokens, where each token corresponds to a specific word or subword.
tokr.batch_decode(res)
['<s> write me a statement of work for Genesys\n\nI am looking for a statement of work for Genesys, can you please provide me with a template?\n\nSure, here is a template for a statement of work for Genesys:\n\nStatement of Work for Genesys Implementation\n\n between [Client Name] and [Consultant Name]\n\nDate: [Date of Agreement]\n\nIntroduction:\n\n[Client Name] (the "Client") and [Consultant Name] (the "Consultant") are entering into this Statement of Work (the "SOW") for the implementation of a Genesys solution for the Client. The purpose of this SOW is to outline the scope of work, deliverables, timeline, and other key elements of the project.\nScope of Work:\nThe scope of work for this project includes the following:\n\n* Installation and configuration of the Genesys solution\n* Customization and development of the Genesys solution to meet the Client\'s specific requirements\n* Testing and quality assurance of the Genesys solution\n* Training and support for the Client\'s staff on the use of the Genesys solution\n* Any additional services required to ensure the successful implementation of the Genesys solution\n\nDeliverables:\nThe following deliverables are expected to be completed by the Consultant as part of this project:\n\n* Installation and configuration of the Genesys solution\n* Customization and development of the Genesys solution to meet the Client\'s specific requirements\n* Testing and quality assurance of the Genesys solution\n* Training and support for the Client\'s staff on the use of the Genesys solution\n* Any additional services required to ensure the successful implementation of the Genesys solution\n\nTimeline:\nThe project is expected to be completed within [timeframe] from the date of this SOW. The following milestones are expected to be achieved during the project:\n\n* [Milestone 1] - [Date]\n* [Milestone 2] - [Date]\n* [Milestone 3] - [Date]\n\nPayment Terms:\nThe Consultant will be paid [amount] for the completion of this project. Payment will be made in [installments] as follows:\n\n* [Installment 1] -']
So far, we have converted our input prompt to tokens, passed the tokens to llm, retrieved the output tokens and de-tokenized back to human english. Thus we are able to see how an LLM takes in a prompt and returns a response by way of tokens.
Part-2: Prompting the Model
Now that we have a basic understanding of how models process input prompts, we can send a large prompt - one that follows a template.
A prompt template is a predefined structure or format for constructing queries or requests in natural language processing (NLP) tasks, particularly when interacting with language models. It serves as a framework to guide users in providing input in a consistent manner. Prompt templates are commonly used in tasks like question answering, text completion, and conversational AI.
Using prompt templates can be beneficial for standardizing interactions with language models, making it easier for users to provide input and receive meaningful responses.
Every model has its own validated prompt templates and using them will help you retrieve the best response for your question. You can find the prompt templates on the model card page in Hugging Face.
Setup Prompt Template
prompt = "Is Typing Indicator supported on Genesys Cloud Messenger?"
prompt_template=f'''[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
{prompt}[/INST]
'''
The instruction section is the text within [INST] <<SYS>> ... <</SYS>> and is used to provide instructions to the assistant. The section [/INST] marks the end of the instruction template. A place holder for the prompt goes in the middle.
Generate Prompt
In thie step, the prompt template is converted to tokenized input (input_ids) using the tokenizer we created in the earlier step.
The model.generate method is used to generate text based on the tokenized input. The generated output is decoded using the tokr.decode method to convert the token IDs back into human-readable text.
print("\n\n*** Generate:")
input_ids = tokr(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokr.decode(output[0]))
*** Generate:
<s> [INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
Is Typing Indicator supported on Genesys Cloud Messenger?[/INST]
I apologize, but I cannot provide information on Typing Indicator's availability on Genesys Cloud Messenger as it is not a known or recognized feature or application within the Genesys ecosystem. Genesys Cloud Messenger is a communication platform designed to help businesses manage customer interactions and communication, and it does not have any built-in features or integrations with Typing Indicator or any other third-party typing indication tools.
However, it is important to note that some third-party applications and browser extensions may offer typing indication capabilities, but these are not officially supported or endorsed by Genesys. If you have any further questions or concerns regarding Genesys Cloud Messenger or any other Genesys products, please feel free to ask.</s>
Pipeline
We can also create a pipeline using the transformers library and set up a text generation pipeline. The pipeline helps us to combine all the steps - tokenizing, generation & decoding into a single function.
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
We can call the pipeline (pipe) with the provided prompt template (prompt_template). The pipeline uses the configured settings, including the pre-trained model, tokenizer, and generation parameters, to generate text.
print(pipe(prompt_template)[0]['generated_text'])
[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
Is Typing Indicator supported on Genesys Cloud Messenger?[/INST]
Thank you for reaching out! I'm happy to help you with your query. However, I must inform you that Typing Indicator is not currently supported on Genesys Cloud Messenger. The platform does not provide built-in support for this feature, and it is not available through any third-party integrations.
Please note that the availability of certain features may change over time, so it's always a good idea to check the official documentation or contact Genesys Support for the latest information.
If you have any other questions or concerns, feel free to ask!
Context Aware Query
We can also enhance our prompt template with a specific structure for asking questions based on a given context. The {context} placeholder is used to insert the specific context for the question. This could be information or details that set the background for the question. We can pass this through our text generation pipeline and observe the output.
prompt = "Are File attachments supported on Web Chat?"
context = "Web messaging allows Files to be attached. User can only attach Images (JPG, GIF, PNG) on both Inbound and outbound messages with 10 MB limit. However for Web chat, File cannot be attached."
prompt_template=f'''[INST] <<SYS>>
Answer the following QUESTION based on the CONTEXT given. If you do not know the answer and the CONTEXT doesn't contain the answer truthfully say "I don't know".<</SYS>>
CONTEXT: {context}
QUESTION: {prompt}[/INST]
'''
print(pipe(prompt_template)[0]['generated_text'])
*** Pipeline:
Based on the context provided, I can confirm that File attachments are not supported on Web Chat. According to the context, Image attachments (JPG, GIF, PNG) are allowed for inbound and outbound messages with a 10 MB limit. However, Web chat is not one of the supported channels for attaching files. Therefore, the answer to the question is "No," File attachments are not supported on Web Chat.
As we can see, the model is answering the users question based on the context provided. It is still using the llama2 pretrained weights to form the sentence properly, however it is responding based on the knowledge (context) we provided. What if we automate the context based on the user prompt? Won’t it make the whole model more knowledgeable, that it answers questions confidently and accurately without making up (hallucinating) answers. By automating context, we can save ourselves from costly fine-tuing and rely on the pretrained weights for grammatically correct sentence formation. This is the intuition behind ‘Retrieval Augmented Generation’ or RAG! In the next section we can see how we can ‘automate the context’ so that context text is relevant to the user prompt.
Part-3: Setting up a Knowledge Database
As we can see for Context Aware Query to work we need to maintain a Knowledge Database from which we can retrieve information that is relevant to user’s prompt. Consider this as an external long-term memory of our LLM.
We can implement this knowledge database using a Vector Database which can store vector embeddings. This will help us retrieve semantically relevant information to our users question. Before we dig in further on how we can implement this vector database, we have to understand what vector embeddings are first.
What are Vector Embeddings?
Word embeddings or vector embeddings are representations of words in a continuous vector space. In other words, Vector embeddings are a way to represent words and whole sentences in a numerical manner. These embeddings capture semantic relationships between words and allow machine learning models to work with words in a way that preserves their meaning.
How Vector Embeddings captures Semantic Meaning?
Word embeddings represent words as vectors in a continuous space. Each word is assigned a vector, and similar words are placed close to each other in this vector space. For example, in a good embedding space, the vectors for “king” and “queen” should be close to each other.
To create these vectors embeddings and store it in a knowledge database, we follow a simple three-step process:
- Load the documents/content and split we want to store in knowledge database
- Use an embedding model to convert the loaded documents to vector embeddings
- Store the resulting vector embeddings into the knowledge database
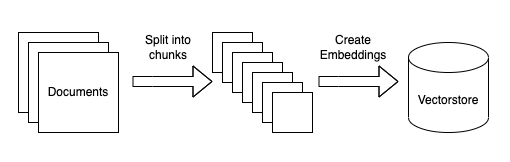
You might ask why do we need to split the loaded documents? Well, for RAG to work we only want to retrieve the paragraph or few lines of text that is most relevant instead of retrieving the whole document.
Document Loading
In this step, we are using a document loader WebBaseLoader from the langchain library to fetch and load documents from web URLs.
from langchain.document_loaders import WebBaseLoader
# Load URLs
loaders = [
WebBaseLoader("https://help.mypurecloud.com/articles/configure-messenger/"),
WebBaseLoader("https://help.mypurecloud.com/articles/deploy-messenger/")
]
docs = []
for loader in loaders:
docs.extend(loader.load())
print("Number of documents:{}".format(len(docs)))
print("Page size of document:{}".format(len(docs[0].page_content)))
print("Sample Document:{}".format(docs[0].page_content[5000:5500]))
Number of documents:2
Page size of document:12305
Sample Document:t language. Messenger attempts to automatically detect the customer’s languages from the browser preferences. If the detected language matches any supported language, the Messenger applies the corresponding localized labels to the UI elements. If the detected language does not match any supported language, the Messenger shows UI labels in the default language. For more information, see Genesys Cloud supported languages.
Click Edit Labels and optionally customize predefined Messenger labels when
Document Splitting
The below code uses the RecursiveCharacterTextSplitter from the langchain to split text into chunks, for processing large texts in smaller, more manageable pieces. Moreover, by converting smaller chunks of text into vector embeddings, we can retrieve this chunk and use it in our context aware query.
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)
splits = text_splitter.split_documents(docs)
print("Total Number of Splits:{}".format(len(splits)))
Total Number of Splits:17
Create Embeddings
Here we will use HuggingFaceEmbeddings, which uses a “sentence-transformers/all-MiniLM-l6-v2” to generate embeddings for a text document.
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
Test Sentence Transformer embedding function
text = "This is a test document."
query_result = embeddings.embed_query(text)
query_result[:3]
[-0.04895172268152237, -0.039861902594566345, -0.02156277559697628]
As we can see the text has been converted to vector embeddings which is a numerical set of values.
Store Embeddings
To leverage the embeddings effectively, we use Chroma, a vector database. The code below creates a vector database from split documents, with the vectors generated using the HuggingFaceEmbeddings instance. This chroma db allows for efficient storage and retrieval of vector representations. Chroma DB loads the vector database and creates a flat file. Note that this flat file is loaded into
from langchain.vectorstores import Chroma
#set database directory
persist_directory = 'docs/chroma/'
vectordb = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory=persist_directory
)
Similarity Search Test
We will perform a similarity search using the vectordb created with Chroma to find documents similar to a given question.The k=3 parameter indicates to retrieve the top 3 most similar documents.
question = "Can I add a brand logo to web message?"
docs = vectordb.similarity_search(question,k=3)
docs[0].page_content
'Under Messenger Homescreen, select whether you want the Messenger to display the home screen. When you turn on this feature, configure the brand logo, customize predefined Messenger labels, and enable the Knowledge App. For more information, see Messenger Homescreen and knowledge articles overview.\nUnder Add a logo, select the required image to use as the brand logo. When you enable this option, the image appears in the home screen and throughout the knowledge base. The images must be in\xa0.JPG, .PNG, or .GIF formats and 512 KB or less. Images\xa0larger than 200 x 70\xa0pixels will be resized.\nUnder Humanize your Conversation, select whether to display a participant name and avatar with the messages that route to your customers. When this feature is on, optionally define a bot name and custom avatar. To configure agent profiles, see Add an agent alias and image. Images must be in .JPG, .PNG, or .GIF formats. Minimum recommended size for images is 75 x 75 pixels.\nUnder Select your Messenger Color, to configure the Messenger color according to your organization’s preference, perform one of the following steps.Note:\xa0 The primary color affects the appearance of the Messenger interface (for example, header, background color of the launcher button, and customer’s message bubble).\xa0\n\n\nManually enter the web color code (in #HEX notation).\nUse the color picker to select the primary color that best matches your brand.'
Part-4: Retrieval Augmented Generation
Context Aware Prompt Template
Before we test RAG, we will also create a function which takes a prompt as input, performs a similarity search on the vector database (vectordb), extracts the content of the most similar document, and returns a prompt template for answering a question based on that context. This will be the function we will use to convert the user prompt to prompt template that we will pass to our language model.
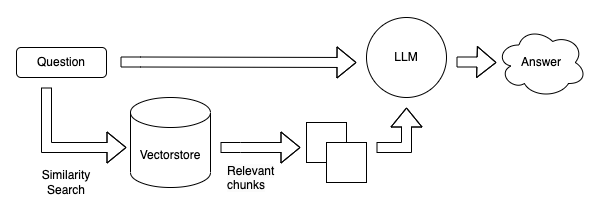
def create_prompt_template(prompt):
context = vectordb.similarity_search(prompt,k=3)[0].page_content
prompt_template=f'''[INST] <<SYS>>
Answer the following QUESTION based on the CONTEXT given. If you do not know the answer and the CONTEXT doesn't contain the answer truthfully say "I don't know".<</SYS>>
CONTEXT: {context}
QUESTION: {prompt}[/INST]
'''
return prompt_template
create_prompt_template("Are File attachments supported on web messaging?")
'[INST] <<SYS>>\n Answer the following QUESTION based on the CONTEXT given. If you do not know the answer and the CONTEXT doesn\'t contain the answer truthfully say "I don\'t know".<</SYS>>\n CONTEXT: Under\xa0Rich Text Formatting, select whether to allow rich text formatting. For more information, see Markdown syntax for rich text in Messenger.\nUnder Automatically Start Conversations, select whether conversations start automatically when the user expands the Messenger window. This setting works best when you configure Architect’s inbound message flow to send automatic greetings. When this feature is off, conversations start when the user sends the first message. Note:\xa0To improve customer experience, Genesys recommends that you configure an initial welcome message with Architect’s Send Response action available from your inbound message flow prior to a Call Bot Flow action.\xa0\nUnder Attachments, select whether to allow JPG, PNG, or GIF image attachments from customers.\xa0Note: To enable image attachments for web messaging, as an admin user, ensure that your default supported content profile also includes at minimum JPG, PNG, and GIF as allowed extensions for both inbound and outbound direction. This default provisioning is necessary in addition to enabling attachment support on Messenger. \nUnder Typing Indicators, select whether to inform the other party when a reply is being typed. For more information about agent-specific permissions, see Work with message interactions.\nUnder Predictive Engagement, select whether to enable the Messenger to collect data about customer activity on your website. Predictive Engagement uses this data to track and manage customer activity.\n\n QUESTION: Are File attachments supported on Messenger?[/INST]\n\n\n '
RAG Validation
Now that we have all the components in place, we can test our RAG and see how it works. As seen from the below examples, the llama2 language model is able to confindently respond on enterprise knowledge that was never part of its training data. Hence, this is a small demo of how RAG works. You can extend this with langchain and implement conversational chain where user can ask followup questions.
prompt = "Are File attachments supported on web messaging?"
prompt_template = create_prompt_template(prompt)
print(pipe(prompt_template)[0]['generated_text'])
[INST] <<SYS>>
Answer the following QUESTION based on the CONTEXT given. If you do not know the answer and the CONTEXT doesn't contain the answer truthfully say "I don't know".<</SYS>>
CONTEXT: Under Rich Text Formatting, select whether to allow rich text formatting. For more information, see Markdown syntax for rich text in Messenger.
Under Automatically Start Conversations, select whether conversations start automatically when the user expands the Messenger window. This setting works best when you configure Architect’s inbound message flow to send automatic greetings. When this feature is off, conversations start when the user sends the first message. Note: To improve customer experience, Genesys recommends that you configure an initial welcome message with Architect’s Send Response action available from your inbound message flow prior to a Call Bot Flow action.
Under Attachments, select whether to allow JPG, PNG, or GIF image attachments from customers. Note: To enable image attachments for web messaging, as an admin user, ensure that your default supported content profile also includes at minimum JPG, PNG, and GIF as allowed extensions for both inbound and outbound direction. This default provisioning is necessary in addition to enabling attachment support on Messenger.
Under Typing Indicators, select whether to inform the other party when a reply is being typed. For more information about agent-specific permissions, see Work with message interactions.
Under Predictive Engagement, select whether to enable the Messenger to collect data about customer activity on your website. Predictive Engagement uses this data to track and manage customer activity.
QUESTION: Are File attachments supported on web messaging?[/INST]
Based on the context provided, I can confirm that File attachments are supported on web messaging. According to the passage, under the Attachments section, it is explicitly stated that JPG, PNG, and GIF image attachments are allowed from customers. This implies that other types of file attachments may also be supported, but further clarification is not provided in the given context. Therefore, my answer to the question is: Yes, File attachments are supported on web messaging.
prompt = "Can agents ask the user to take control of their screen?"
prompt_template = create_prompt_template(prompt)
print(pipe(prompt_template)[0]['generated_text'])
[INST] <<SYS>>
Answer the following QUESTION based on the CONTEXT given. If you do not know the answer and the CONTEXT doesn't contain the answer truthfully say "I don't know".<</SYS>>
CONTEXT: Under Co-browse, select whether to allow agents to request to view a customer’s screen. After you enable this option, you can also enable the agents to request control of the user’s screen. Additional configuration options include masking of sensitive fields and limiting fields or buttons to read-only, even when the agent has control of the sharer’s browser. Note: Predictive Engagement and co-browse features are not currently available for Mobile Messenger.
To allow only authenticated users to start a web messaging session with agents, under Authentication, perform these steps:
QUESTION: Can agents ask the user to take control of their screen?[/INST]
Based on the context provided, the answer is "Yes." Agents can ask the user to take control of their screen after enabling the option to request control of the user's screen.
prompt = "Can I use my company's logo on web messaging for the purpose of branding?"
prompt_template = create_prompt_template(prompt)
print(pipe(prompt_template)[0]['generated_text'])
[INST] <<SYS>>
Answer the following QUESTION based on the CONTEXT given. If you do not know the answer and the CONTEXT doesn't contain the answer truthfully say "I don't know".<</SYS>>
CONTEXT: Under Messenger Homescreen, select whether you want the Messenger to display the home screen. When you turn on this feature, configure the brand logo, customize predefined Messenger labels, and enable the Knowledge App. For more information, see Messenger Homescreen and knowledge articles overview.
Under Add a logo, select the required image to use as the brand logo. When you enable this option, the image appears in the home screen and throughout the knowledge base. The images must be in .JPG, .PNG, or .GIF formats and 512 KB or less. Images larger than 200 x 70 pixels will be resized.
Under Humanize your Conversation, select whether to display a participant name and avatar with the messages that route to your customers. When this feature is on, optionally define a bot name and custom avatar. To configure agent profiles, see Add an agent alias and image. Images must be in .JPG, .PNG, or .GIF formats. Minimum recommended size for images is 75 x 75 pixels.
Under Select your Messenger Color, to configure the Messenger color according to your organization’s preference, perform one of the following steps.Note: The primary color affects the appearance of the Messenger interface (for example, header, background color of the launcher button, and customer’s message bubble).
Manually enter the web color code (in #HEX notation).
Use the color picker to select the primary color that best matches your brand.
QUESTION: Can I use my company's logo on web messaging for the purpose of branding?[/INST]
Answer: Yes, you can use your company's logo on Web Messaging for the purpose of branding. Under "Add a logo," you can select the required image to use as the brand logo. When you enable this option, the image appears in the home screen and throughout the knowledge base. The images must be in.JPG,.PNG, or.GIF formats and 512 KB or less. Images larger than 200 x 70 pixels will be resized.
Reference
- LangChain RAG
- How to use Retrieval-Augmented Generation (RAG) with Llama 2 link
- Amazon Bedrock Sample Notebooks link
- ChromaDB Embedding
- ChromaDB Tutorial
Twitter Facebook LinkedIn
Comments