
LLM Based Enterprise Search Solution using RAG In AWS
Introduction
- Within the field of Generative AI, Text generation, especially Enterprise Search for ChatBots, Agent Assits, Internal Forums is a very common use case.
- Training LLMs on Enterprise data will not be effective as it is very complex and knowledge-intensive task.
- Retrieval Augmented Generation (RAG) is concept introduced by Meta AI researchers to combine an information retrieval component with a text generator model. RAG can be fine-tuned and its internal knowledge can be modified in an efficient manner and without needing retraining of the entire model.
Overview of Solution
- Solution uses transformer model for answering questions
- Zero-shot prompting for generating answers from untrained data
- Benefits of the solution:
- Accurate answers from internal documents
- Time-saving with Large Language Models (LLMs)
- Centralized dashboard for previous questions
- Stress reduction from manual information search
Retrivel Augmented Generation (RAG)
- Retrieval Augmented Generation (RAG) enhances LLM-based queries
- Addresses shortcomings of LLM-based queries
- RAG can be implemented using Amazon Kendra
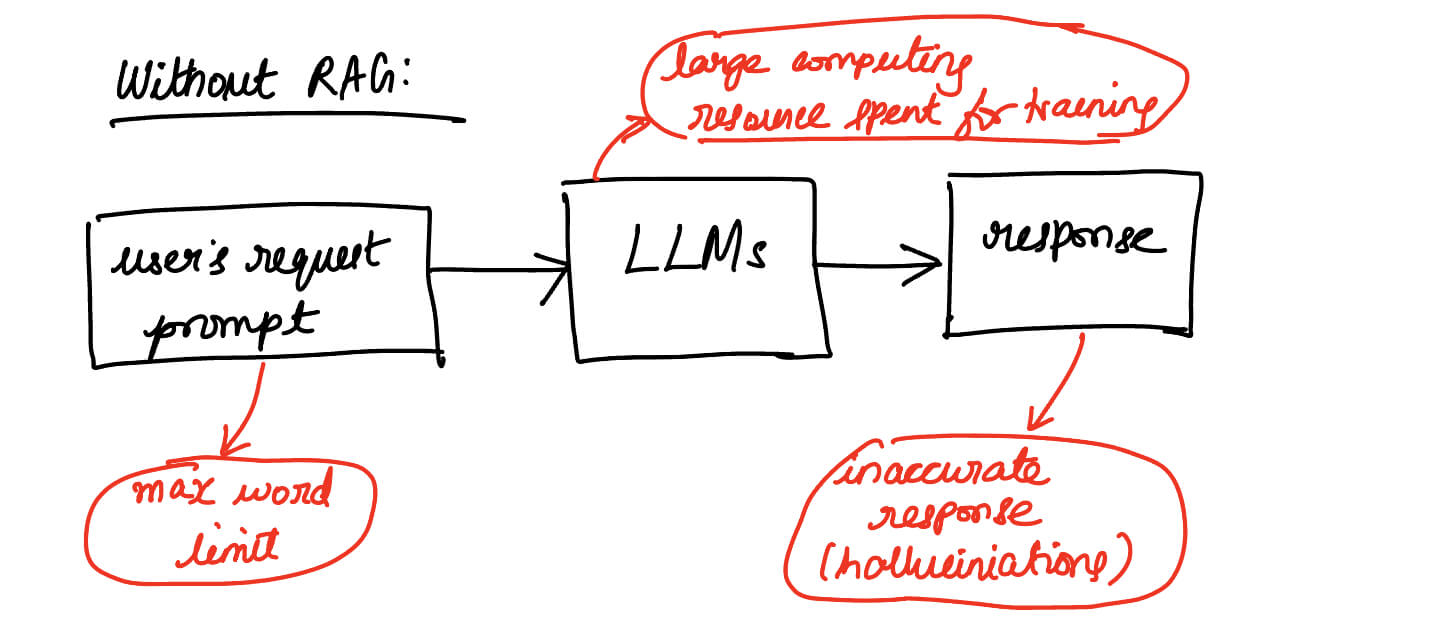
- Risks and limitations of LLM-based queries without RAG:
- Hallucinations (probability based answering) leads to inaccurate answers
- Multiple data source challenges
- Security and privacy concerns: possibility of unintentionally surfacing personal or sensitive information
- Data relevance: information is often not current
- Cost considerations for deployment: Running LLMs can require substantial computational resources
Why does RAG work?
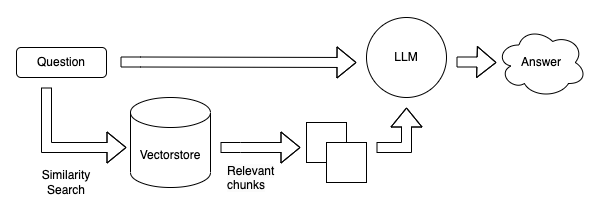
- An application using the RAG approach retrieves information most relevant to the user’s request from the enterprise knowledge base or content, bundles it as context along with the user’s request as a prompt, and then sends it to the LLM to get a GenAI response.
- LLMs have limitations around the maximum word count for the input prompt, therefore choosing the right passages among thousands or millions of documents in the enterprise, has a direct impact on the LLM’s accuracy.
Why Amazon Kendra is required?
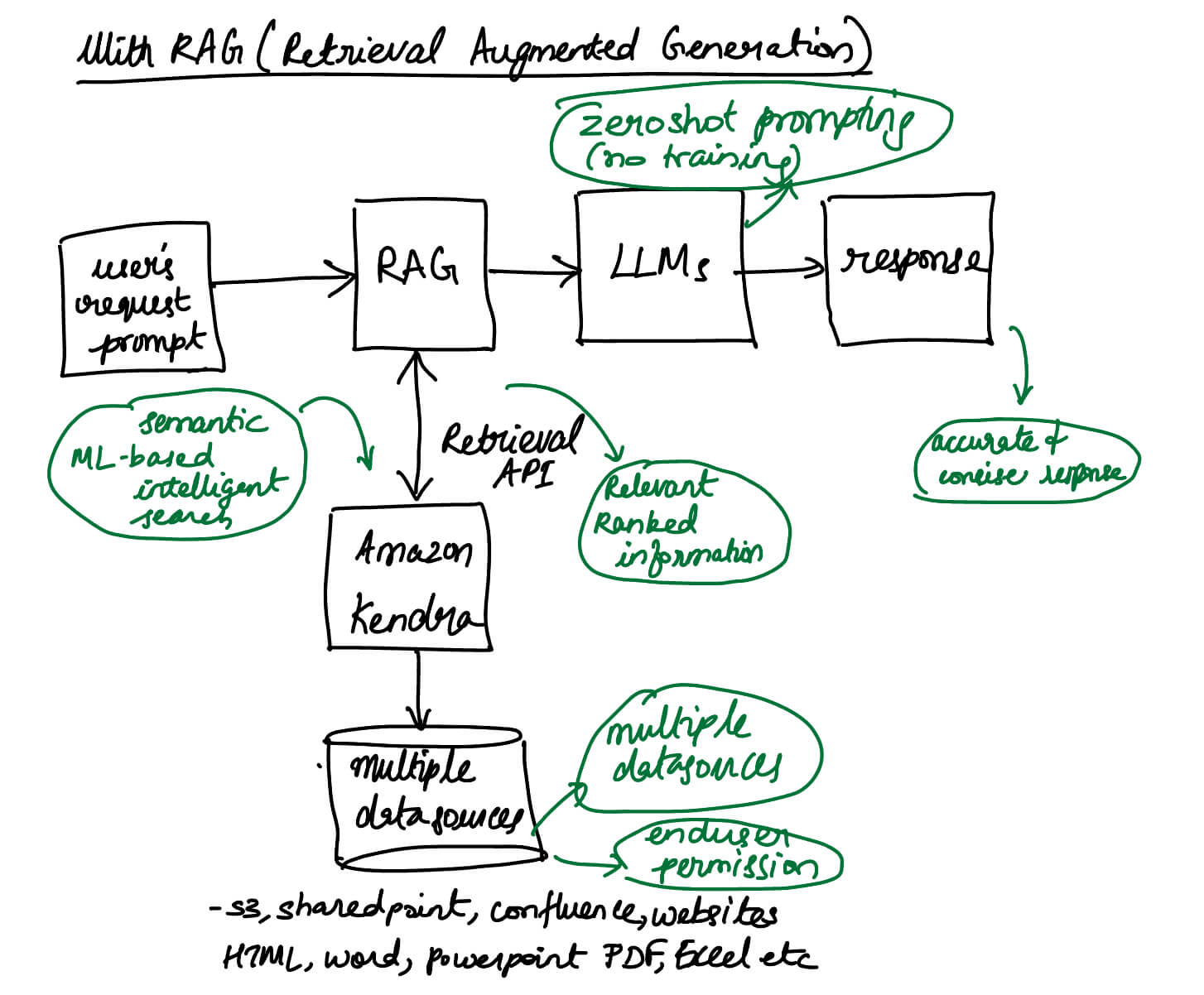
- We have already established Effective RAG (Retrieval Augmented Generation) is crucial for accurate AI responses.
- Content retrieval is a key step for providing context to the AI model.
- Amazon Kendra index is used to ingest enterprise unstructured data from data sources such as wiki pages, MS SharePoint sites, Atlassian Confluence, and document repositories such as Amazon S3.
- Amazon Kendra’s intelligent search plays a vital role in this process.
- Kendra offers semantic search, making it easy to find relevant content.
- It doesn’t require advanced machine learning knowledge.
- Kendra provides a Retrieve API for obtaining relevant passages.
- It supports various data sources and formats, with access control.
- It integrates with user identity providers for permissions control.
Solution Workflow
- User sends a request to the GenAI app.
- App queries Amazon Kendra index based on the request.
- Kendra provides search results with excerpts from enterprise data.
- App sends user request and retrieved data to LLM.
- LLM generates a concise response.
- Response is sent back to the user.

Choice of LLM
- Architecture allows choosing the right LLM for the use case.
- LLM options include Amazon partners (Hugging Face, AI21 Labs, Cohere) and others hosted on Amazon SageMaker endpoints.
- With Amazon Bedrock, choose Amazon Titan, partner LLMs (e.g., AI21 Labs, Anthropic) securely within AWS.
- Benefits of Amazon Bedrock: serverless architecture, single API for LLMs, and streamlined developer workflow.
GenAI App
- For the best results, a GenAI app needs to engineer the prompt based on the user request and the specific LLM being used.
- Conversational AI apps also need to manage the chat history and the context.
- Both these tasks can be accomplished using LangChain
What is LangChain?
- LangChain is an open-source framework for developing applications powered by language models. It enables applications that are context Aware and Reason.
- Developers can utilize LangChain frameworks for LLM integration and orchestration.
- AWS’s AmazonKendraRetriever class implements a LangChain retriever interface, which applications can use in conjunction with other LangChain interfaces such as chains to retrieve data from an Amazon Kendra index. - AmazonKendraRetriever class uses Amazon Kendra’s Retrieve API to make queries to the Amazon Kendra index and obtain the results with excerpt passages that are most relevant to the query.
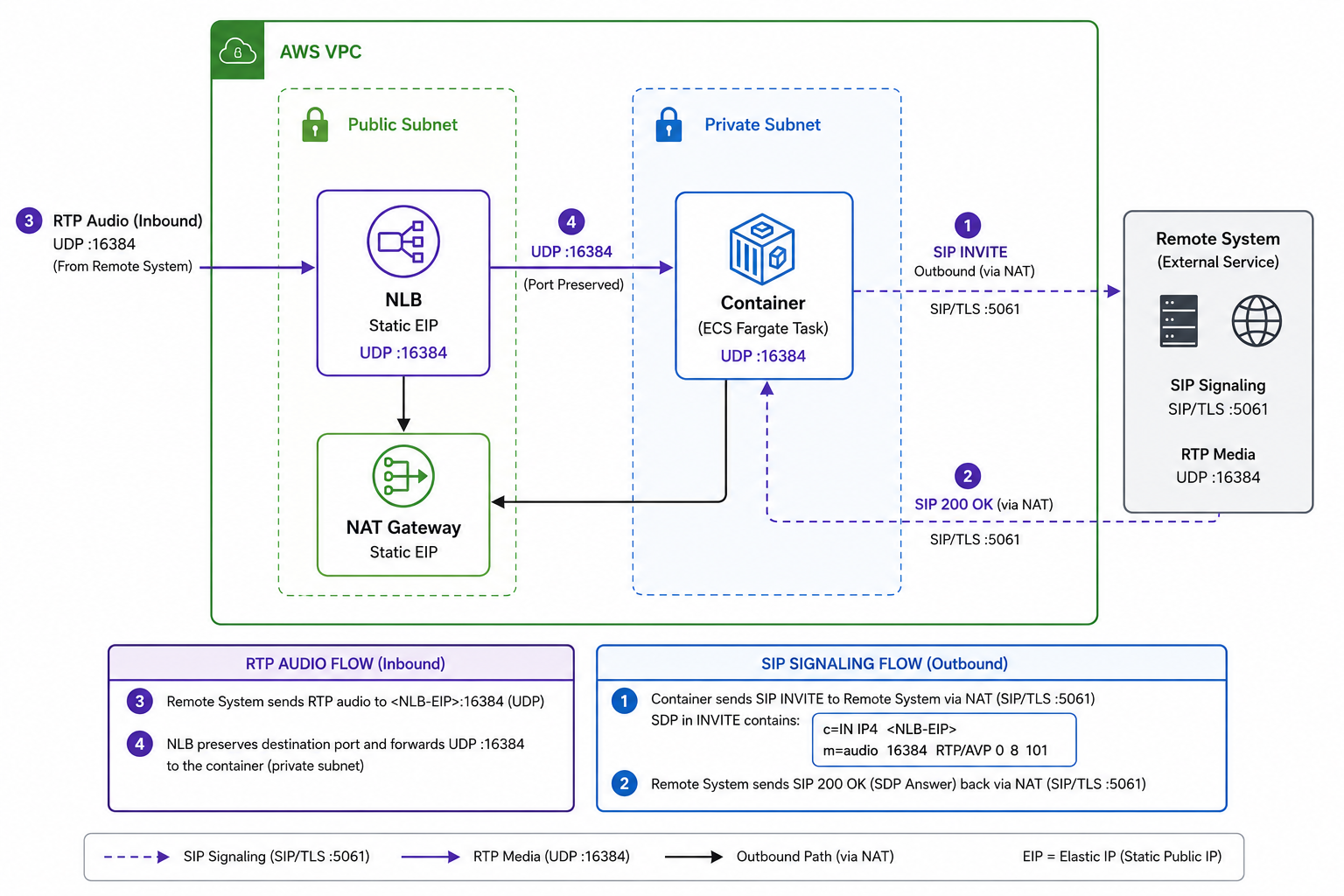
A Complete Sample AWS Workflow:
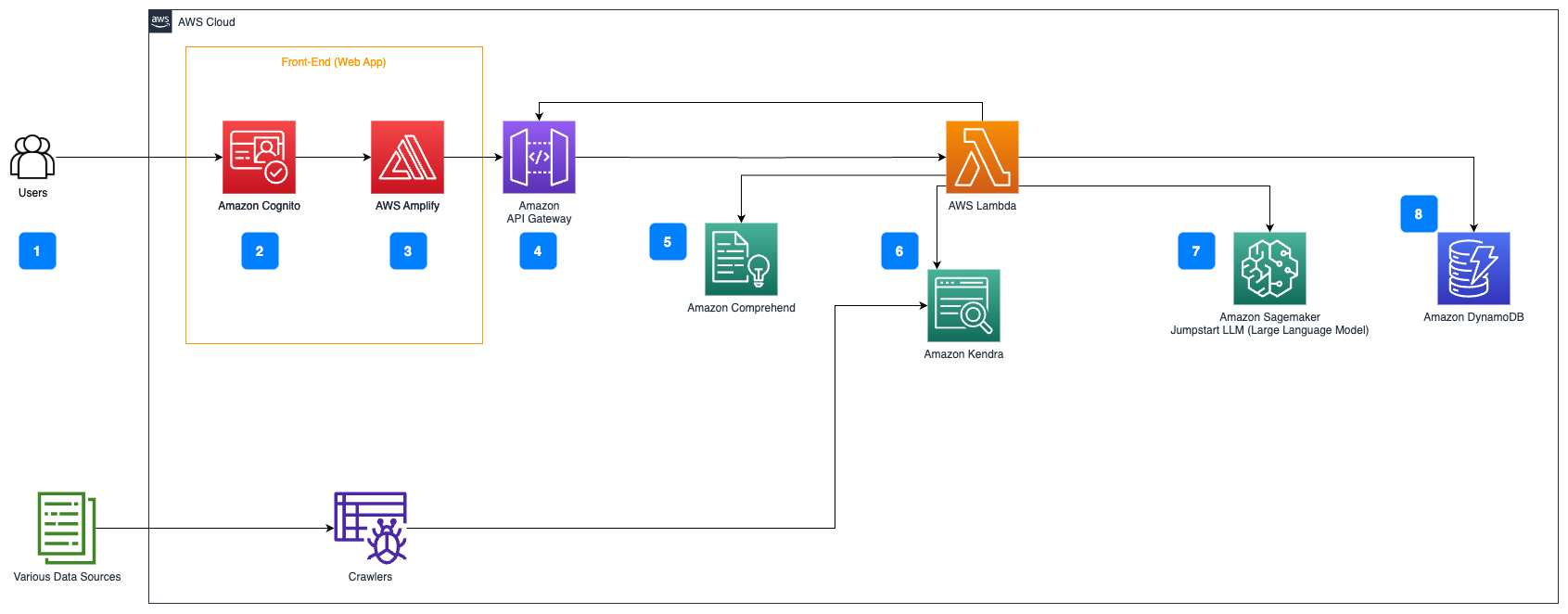
AWS Workflow of Question Answering over Documents:
- User query via web interface
- Authentication with Amazon Cognito
- Front-end hosted on AWS Amplify
- Amazon API Gateway with authenticated REST API
- PII redaction with Amazon Comprehend:
- User query analyzed for PII
- Extract PII entities
- Information retrieval with Amazon Kendra:
- Index of documents for answers
- LangChain QA retrieval for user queries
- Integration with Amazon SageMaker JumpStart:
- AWS Lambda with LangChain library
- Connect to SageMaker for inference
- Store responses in Amazon DynamoDB with user query and metadata
- Return response via Amazon API Gateway REST API.
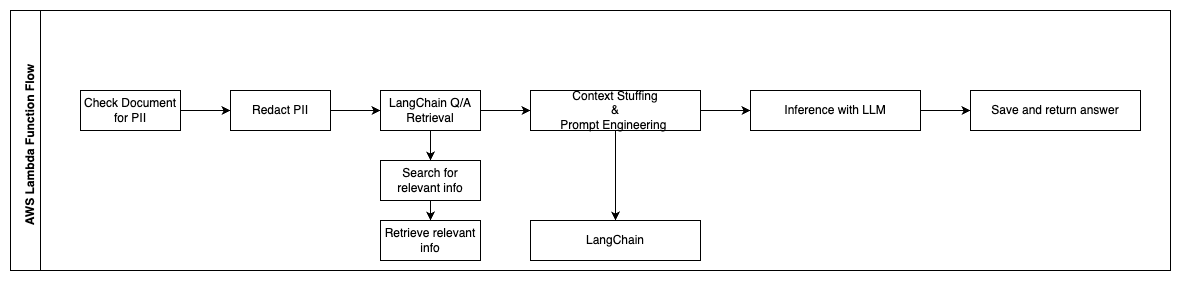
AWS Lambda Functions Flow:
- Check and redact PII/Sensitive info
- LangChain QA Retrieval Chain
- Search and retrieve relevant info
- Context Stuffing & Prompt Engineering with LangChain
- Inference with LLM (Large Language Model)
- Return response & Save it
Security in this Workflow
- Security best practices documented in Well-Architected Framework
- Amazon Cognito for authentication
- Integration with third-party identity providers are available
- Traceability through user identification
- Amazon Comprehend for PII detection and redaction
- Redacted PII includes sensitive data
- User-provided PII is not stored or used by Amazon Kendra or LLM
References:
- Lewis, P. S. H., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. CoRR, abs/2005.11401. https://arxiv.org/abs/2005.11401
- LinkedIn: Transforming Question Answering with OpenAI and LangChain: Harnessing the Potential of Retrieval Augmented Generation (RAG) link
- AWS: Simplify access to internal information using Retrieval Augmented Generation and LangChain Agents link
- AWS: Quickly build high-accuracy Generative AI applications on enterprise data using Amazon Kendra, LangChain, and large language models (Step-By-Step Tutorial) link
- LangChain link
- AWS Kendra Langchain Extensions - Github link
- AWS Kendra Demo YouTube link
- Machine Learning How to Start in AWS link
- AWS ML Workshop With UseCases link
Twitter Facebook LinkedIn
Comments